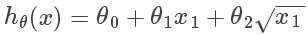背景
当某个离散的数值与若干特性存在一定的依存关系时,可以采用线性回归的方法对问题进行建模。如房价与房子的大小、房间数等因素相关,因此可以采用线性回归的方法对问题建模,得到一个房价的预测模型。
在机器学习中,线性回归属于监督学习中的回归问题,即通过对已有数据集(训练集)的训练学习,使机器能够对离散的数值进行判断和预测。
问题如根据已售房子数据,根据房子面积和房间数对房价进行估值:
| 面积(X1/平米) | 房间数(X2/个) | 房价(Y/万) |
|---|---|---|
| 123 | 4 | 250 |
| 150 | 5 | 320 |
| 87 | 3 | 160 |
| … | … | … |
源自 Andrew Ng 公开课整理
模型简介
对于有 n 个特征属性的元素,令其假设/模型函数(hypothesis function)如下,其中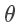 为待求解的值:
为待求解的值:
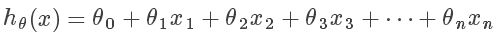
采用向量来表示,其中 x0 = 1,T 表示矩阵转置:

由于现代计算机多数编程语言均有函数库对矩阵运算进行了相关优化,如利用多核CPU并行加速等,所以大多数运算应尽量采用矩阵的方式,而不是采用一般的多重循环来实现
Octave代码实现:
% x 为特征值列向量
% theta 为假设变量列向量
% 非矩阵形式
function prediction = hypothesis(x, theta)
prediction = 0.0;
for j = 1:n+1,
prediction += theta(j) * x(j)
% 矩阵形式
function prediction = hypothesis(x, theta)
prediction = theta' * x
对于一组有 m 条记录的训练集,可以将训练集中的特征值组成一个矩阵,为列向量。如 m = 3,n = 2的:
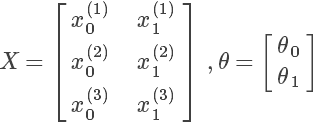
其中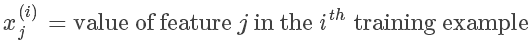 表示第 j 个特征的第 i 个训练实例
表示第 j 个特征的第 i 个训练实例
则所有训练集带到假设函数中取得的假设值的列向量如下:
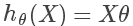
其中若训练集中有 n 个特征,有 m 条实例,则矩阵 X 为 m x (n+1) 维矩阵。
代价函数
代价函数(Cost function)用来描述通过假设函数求得的值与实际值之间的差距,其定义如下,其中 m 为训练集中实例条目的个数:
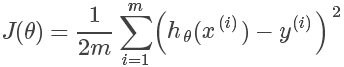
其和统计中的方差异曲同工,其中求平方是为了防止出现累加中正负相抵的情况,除以2是为了求导后的公式好看。
由于 X 和 Y 均在训练集中,数值已知,因此代价函数就是关于的二次函数
矩阵的表示方式如下:
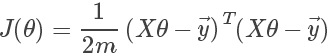
其中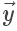 为真实值的列向量。
为真实值的列向量。
Octave代码实现:
function J = costFunctionJ(X, y, theta)
% X 为前文设置的训练集特征值矩阵
% y 为训练集结果列向量
% theta 为参数列向量
m = size(X,1); % 训练集数量
predictions = X*theta; % 预测结果列向量
squares = (predictions-y).^2; % 平方差
J = 1/(2*m) * sum(sqrErrors); % 代价函数取值
或
function J = costFunctionJ(X, y, theta)
% X 为前文设置的训练集特征值矩阵
% y 为训练集结果列向量
% theta 为参数列向量
m = size(X,1); % 训练集数量
e = (X*theta-y) % 插值列向量
J = 1/(2*m) * e' * e; % 代价函数取值
问题求解
模型的确定就是求为何值时,代价函数取值最小。由于其为二次函数,是凸函数,存在最小值。主要有两种方法:
- 最小二乘法(Least squares)。通过数学推导直接计算所得。
- 梯度下降法(Gradient Descent)。根据函数曲线斜率,不断迭代移动,直到逼近曲线最低点。(有种不断带入数值尝试,最终试到最优解的意思)
最小二乘法
结果
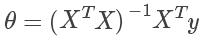
其中 X 如前文所述,若训练集中有 n 个特征,有 m 条实例,则矩阵 X 为 m x (n+1) 维矩阵,而 y 为 m 维列向量,因此最终的为 n+1 维列向量,符合前文所述。
其中运行最耗费时间的是矩阵的逆运算,时间复杂度为 O(n^3),因此如果特征数量(不是训练集实例个数)非常庞大计算很耗时。
Octave代码实现:
pinv(X'*X)*X'*y
其中pinv为伪拟,inv为求拟,在X可逆时两者结果相同,X不可逆时inv无解,pinv仍可以求得结果
计算中矩阵不可逆的原因
背景知识和线性代数有关,总而言之,是存在冗余的特征。
- 有多个特征是(或非常接近)线性相关(例如某个特征所有实例是另一个特征的若干倍),这时应删除其余相关的特征。
- 特征过多,如实例的数量小于等于特征的数量(m<=n),这种情况应删除一些特征,或使用正则化方法(regularization)。
梯度下降法
迭代计算,直到汇聚到某一个值,即两次计算的结果差距很小:
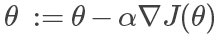
其中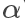 为人为设定的学习(变化)速率,
为人为设定的学习(变化)速率,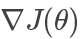 为代价函数关于的偏导(即曲线斜率)。可以理解为通过不断迭代尝试,让以某个速率向代价函数曲线的最低点移动。
为代价函数关于的偏导(即曲线斜率)。可以理解为通过不断迭代尝试,让以某个速率向代价函数曲线的最低点移动。
简要推导
由于:
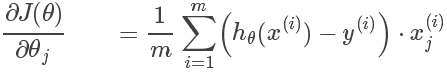
所以求解的结果是:
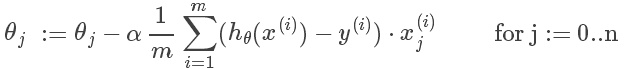
其中由于每个的计算中都包含其它,因此,在正规的梯度下降法中,每次迭代计算使用的都是前一轮迭代的结果,而不是本轮计算产生的值。而采用矩阵计算可以避免这种误解。
由于:
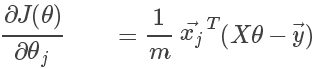
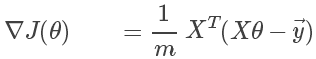
结果
所以最终,只用记住这个就OK。。。:
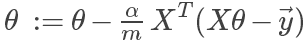
技巧–特征归一化
如果训练集中各各特征的数值差距比较大,如房间大小是房间数量的几十倍,则代价函数的图形以及的变化如下所示:
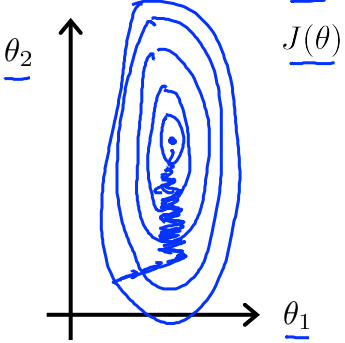
因此,可以将训练集中特征值进行归一化处理,让各各特征在带入运算时取值范围都在[-1,1]。
对于每个特征值,归一化方法如下:
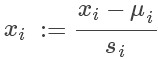
其中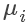 代表训练集中该特征值的均值,
代表训练集中该特征值的均值,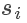 代表训练集中该特征值的最大值与最小值的差值。
代表训练集中该特征值的最大值与最小值的差值。
技巧–学习速率的设计
在正常的计算中,学习速率是不变的,梯度下降计算结果因所在点斜率的变化最终趋于收敛。
然而的大小影响运算的迭代次数。
如果过小,虽然结果是收敛的,但是迭代次数会很多。
如果过大,则结果有可能不收敛。
一般的方法是通过画代价函数与运算迭代次数的曲线来判断学习速率是否合理。代价函数结果应该随迭代次数的增加而减小,最终趋于某一常数
如果出现以下情况,则说明学习速率设置过大 :
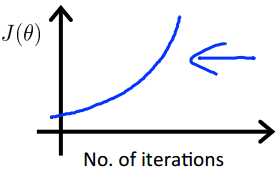
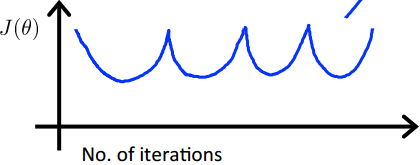
如果经过很多次迭代,计算结果仍没收敛,则说明学习速率设置偏小
两种方法对比
| 最小二乘法 | 梯度下降法 |
|---|---|
| 不需要设置任何参数 | 需要设置学习速率alpha |
| 直接计算结果 | 需要多次迭代运算 |
| 当特征数量庞大时计算慢 | 当特征数量庞大时计算效率仍然可以接受 |
因此当前,在特征数量在上万时应该考虑用梯度下降法,而对于特征数量不多的情况,采用最小二乘法会更为快捷。
引申–多项式回归
利用线性回归建模得到的是假设函数和特征之间是线性的,如有一个特征则函数是一条直线,两个特征则是一个平面。而真实的数据可能和其并一定吻合,如房价和房子大小的关系:
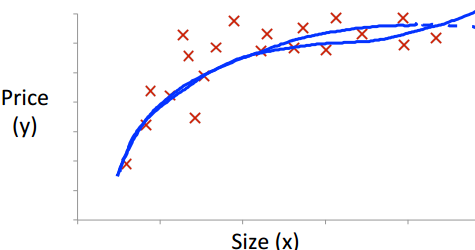
这时采用假设函数: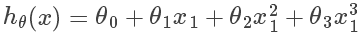 效果会更好。由于二次函数是抛物线,当房子尺寸增大到一定程度是其价格不会减小,因此可以用三次函数拟合。
效果会更好。由于二次函数是抛物线,当房子尺寸增大到一定程度是其价格不会减小,因此可以用三次函数拟合。
其中如果令: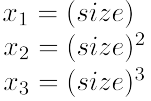
则其又会回归到之前求解线性回归的问题上。
同样,假设函数也可以设置为